
Our research concerns mathematics, computer science, and applications—and especially the intersections among these fields. For example, we develop efficient and reproducible pipelines for large and complex data, and we strive for a better mathematical understanding of contemporary concepts and methods in data science and artificial intelligence.
Find a couple of exemplary topics below.
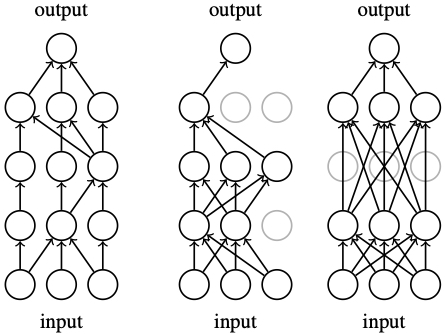 |
Deep LearningDeep learning establishes predictive models that are inspired by neuroscience. It has become one of the most active fields of research. Our role is the development of new concepts and sound theories. We take an interdisciplinary approach, combining statistics, optimization, and concrete applications. |
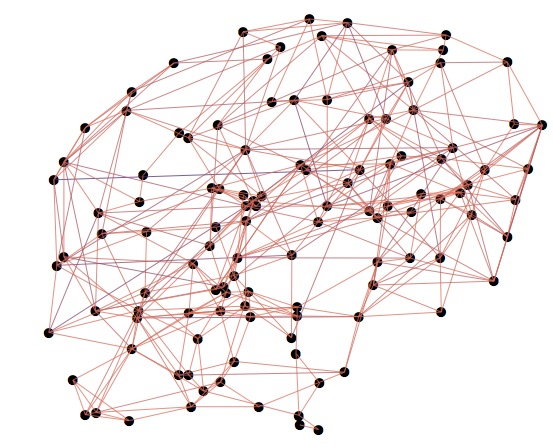 |
Biological NetworksNetwork models describe connections among entities in a system. Such models are used across many scientific disciplines, including economy, sociology, biology, medicine, and physics. We develop general frameworks for network models and investigate their properties in applications. We primarily focus on networks in biology and medicine, such as brain-connectivity networks and gene-regulation networks. |
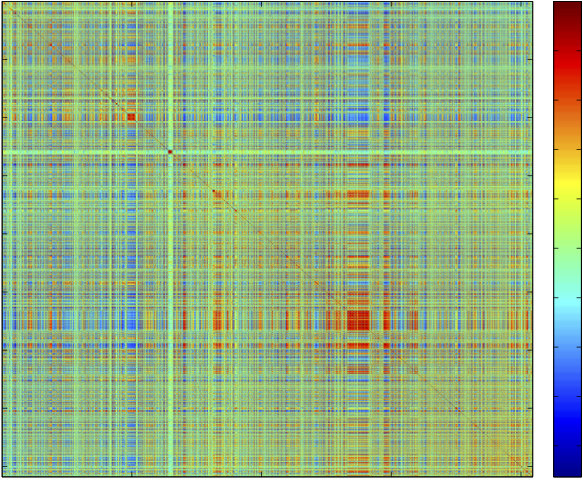 |
High-Dimensional StatisticsThe number of observed parameters in contemporary data sets is often much larger than the number of samples. To obtain good estimates in such settings, all information about the data needs to be incorporated, and the methods need to be carefully calibrated. We develop corresponding statistical tools and equip them with mathematical theory. For example, we establish calibration schemes that satisfy rigorous mathematical bounds. |
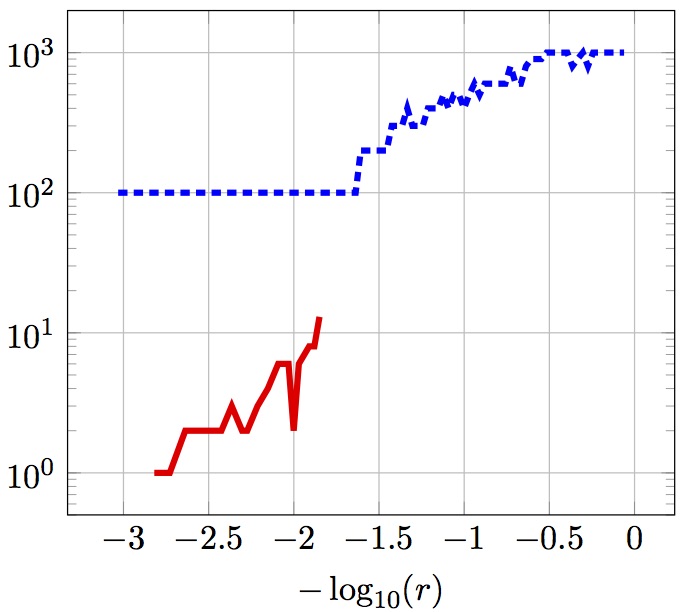 |
Big DataThe advent of high-throughput technologies allows one to collect data at unprecedented frequencies. This leads to enormous data sets that are too large for traditional analysis techniques. We develop algorithms and software that can address these new challenges providing fast analyses even of data with many millions of samples. |
 |
Empirical ProcessesEmpirical processes are mathematical objects that are ubiquitous in statistical theories. We are especially interested in concentration bounds for empirical processes. Classical examples are Bernstein’s and Höffding’s inequalities. In our research, we develop new bounds that relax the assumptions on the underlying model. These bounds serve as a theoretical basis for evaluating statistical methods, both in classical as well as high-dimensional settings. |
